
At Opendoor, we leverage machine learning to price homes that customers sell to us. Because we make real offers on homes worth hundreds of thousands of dollars, it is critical that our models make accurate price estimates.
If our estimates are too low, we are unfair to our customers. If our estimates are too high, we might pay more for the home than the market would allow us to sell it for, and as a result we might lose money. Neither of these outcomes are good, and that’s why we always work hard to improve our models.
A popular way to improve model accuracy is to build multiple models and then compute a weighted average of their estimates. For example, if one model says that a home is worth $295K and another model says the home is worth $305K, we might average the two estimates together to make a final estimate of $300K. This approach is called ensembling.
When it comes to improving accuracy, ensembling is effective. What is probably most surprising is that adding a new model to the ensemble usually helps even if the new model is inferior to all of the original models.
If our models were people
The simplest way to think about ensembles is to imagine that you are in a meeting with two real estate professionals. Both are trying to guess how much a home is worth, and it is your job to reach a conclusion. Amy is smart and has a lot of experience, and she thinks the value is $230K. Bob is newer and doesn’t know as much, and he thinks the value is $220K. Who is closest to the actual market price?
Amy is more likely to be accurate than Bob, but you probably shouldn’t rely only on her answer. Even though Bob doesn’t know as much, he brings a new perspective. Maybe he notices something about the home that Amy has missed. The best thing for you to do is to compromise between the two estimates. Since Amy has more expertise, you should put more weight on her estimate, so that your compromise comes closer to her, maybe around $227.
In some sense, Amy and Bob are both “models”. By choosing a price that is a weighted average of their estimates, you are acting like an ensemble model and will tend to make better decisions. Of course, this approach won’t always lead to better decisions. Sometimes the best answer may have been much closer to Amy’s estimate or closer to Bob’s estimate, or perhaps even more extreme than either one of them. But on average you will tend to make better decisions if you factor in both of their beliefs than if you only pay attention to one.
Putting some numbers to it
Let’s test this with some real numbers. Imagine you have two models, A and B. Sometimes the models make estimates that are 5% too high and sometimes they make estimates that are 5% too low. There is no correlation between the errors of the models. That is, whenever Model A is too high, it is equally likely that Model B will be too high or too low.

As you can see in the table above, these models will on average both be 5% off of what we estimate the market price to be.
However, if you average the two models together, something interesting happens. Whenever both models are too low or too high, the ensemble is also too low or too high. But whenever one model is too low and the other model is too high, the ensemble estimate becomes perfect! As a result, the ensemble model will on average be about 2.5% off of the market price, which is better than either of the original models alone.

Even if you made one of the models slightly worse, for example by turning all the 5’s into 6’s in Model B, the Ensemble would still outperform either model alone, which helps explain why introducing an inferior model can sometimes help. Of course, at a certain point, a model can become so bad that it does more bad than good. But in most cases, adding a new model tends to help.
What this looks like in model space
A final way to explain ensembling is with graphs and a little bit of linear algebra.
In the plot below, we show some simulated errors for 300 homes based on two different models. Each point represents a home. The errors for Model A are shown on the vertical axis and the errors for Model B are shown in the the horizontal axis.

Look at the homes in the top right quadrant. For these homes, both of the models have positive error. As a result, these homes tend to obtain very little benefit from ensembling, as the average estimate will also have positive error. That’s why we call this quadrant the “Meh” Quadrant.
Now look at homes in the top left quadrant. For these homes, Model A gave a positive error and Model B gave a negative error. Because the errors largely cancel each other out, these homes benefit a lot from ensembling. That’s why we call this quadrant the Good Quadrant.
A similar story plays out in the bottom two quadrants.
Quadrants are a useful way to think about this, but to be a bit more precise we need to use a little bit of linear algebra. When you compute an average of two values, you multiply each of the values by 0.5 and then you add them up. One way of thinking about this is that you are taking a dot product of the vector of values with the averaging vector [0.5, 0.5]. And a good way to think about a dot product is that it is proportional to a projection of one vector on to the other. Without getting into the details too much, an average of two numbers is equivalent to 71% of the projection on to [0.5, 0.5]
To show how this plays out graphically, the plot below shows the averaging vector ([0.5, 0.5]), which points to the top right. We have also highlighted one of the homes in dark. For this home, the error from Model A was positive, and the error from Model B was negative. The average of the errors (i.e. the error of the ensemble) is proportional to the projection of the home onto the averaging vector. The projection for this example home is shown as the pink vector pointing to the top right. Notice that it is very small, meaning that the ensemble error for this home (0.091) is also small.

The two models shown in the graph above had errors that were not very correlated. But sometimes two models can have errors that are very correlated, meaning that when one model has e.g. positive error, the other model is also very likely to have positive error. When this happens, the models become somewhat redundant, and there is not much advantage to averaging.
Some insight can be obtained by visualizing models with different degrees of correlation. The animation below shows a fixed Model A, with different variants of Model B, ranging from perfectly correlated with Model A to totally uncorrelated with Model A.
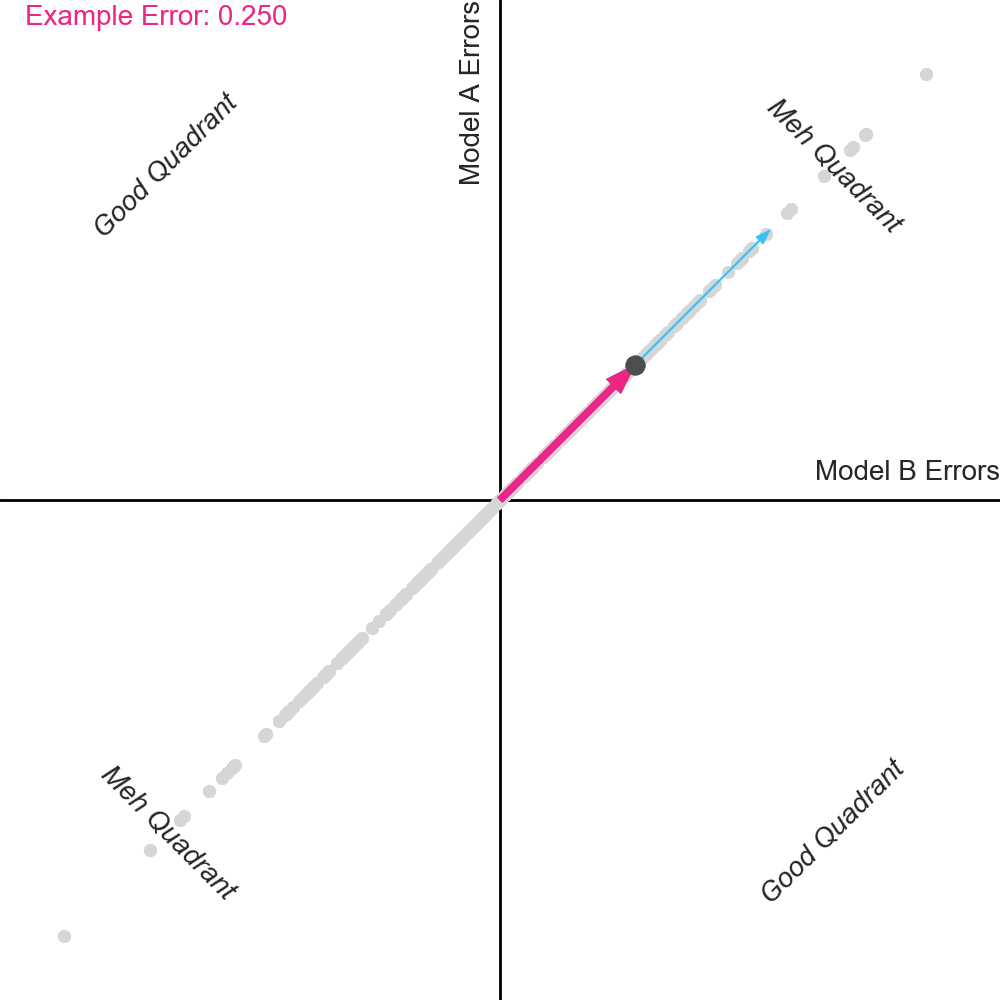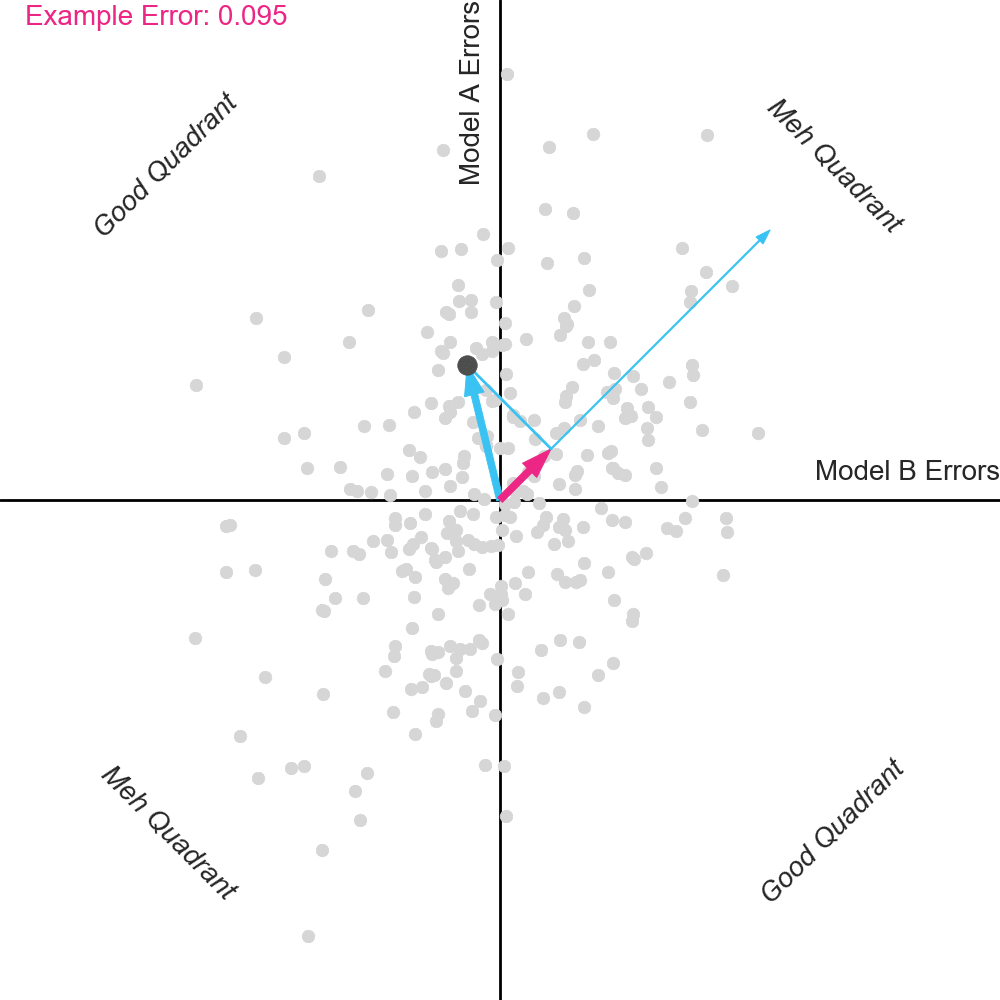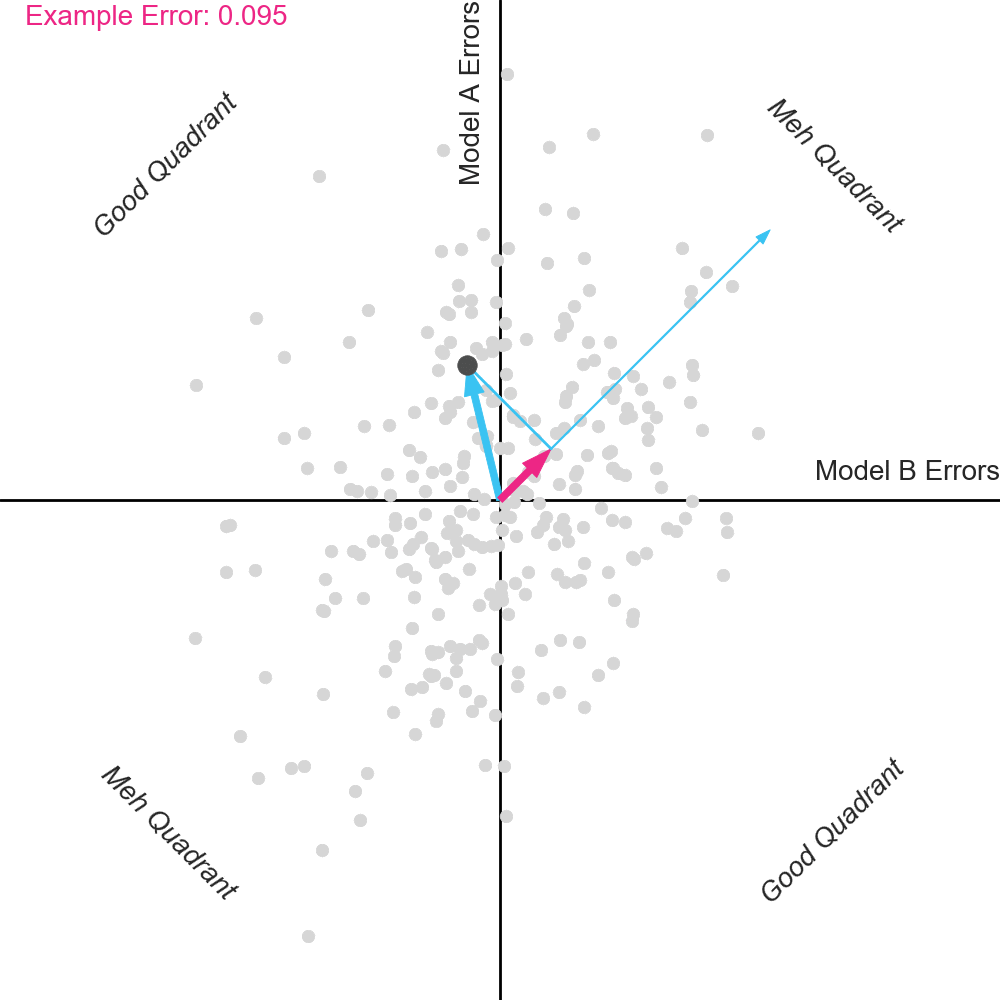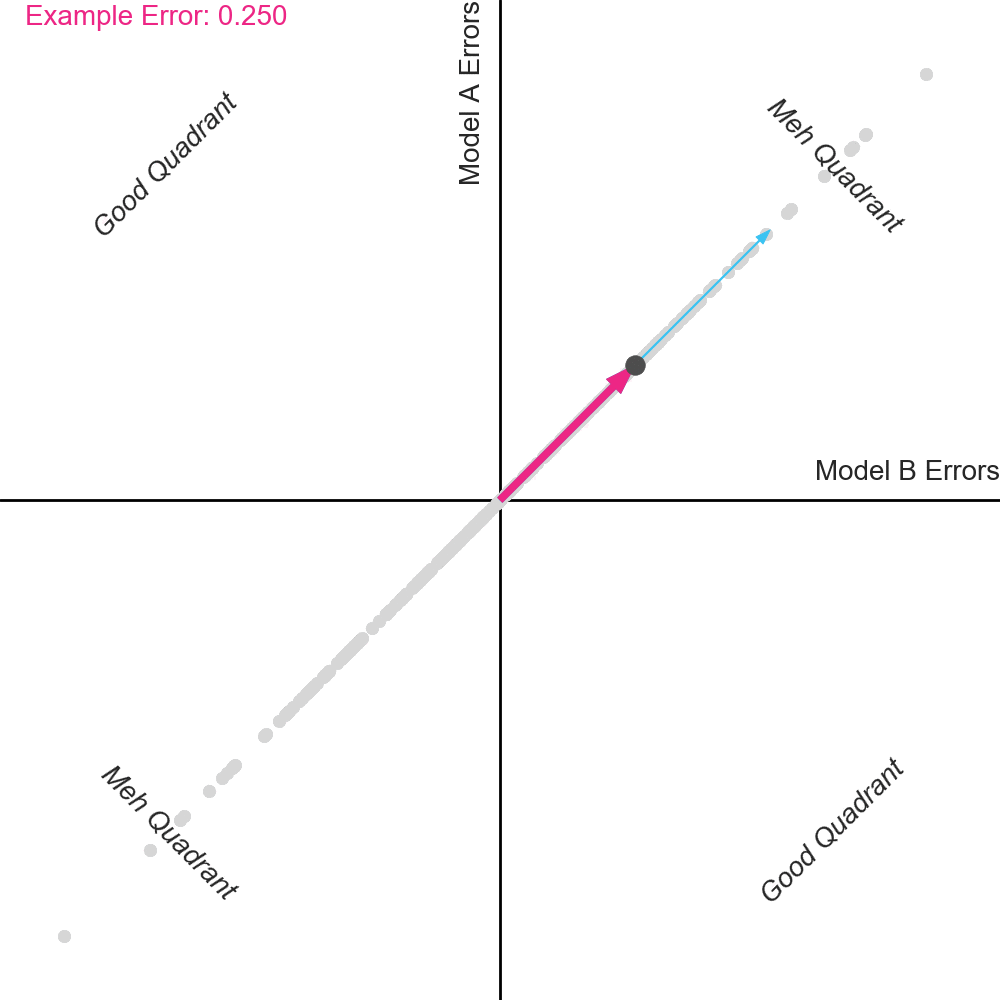
Pay attention to the dots in the top right “Meh” Quadrant when the errors are perfectly correlated. Notice that when the errors begin to separate, some dots move right and some dots move left. But critically, notice that more dots move left than move right. This includes the example dot. The dots that move left reduce their projection on the averaging vector, and thus have improved error.
Why is this happening? The dots in the top right quadrant represent homes on which Model A had positive errors. If you have another model value these homes it’s likely that this other model will have lower (less positive) errors. While a minority of homes might obtain even higher error from the second model, most will get lower error. And critically, the less correlated the second model is with Model A, the bigger the magnitude of this delta, and the bigger the benefit of averaging.
That’s why at Opendoor we strive to use models that are minimally correlated with each other.
Opendoor and ensemble models
Ensembling has always been core to the way Opendoor approaches the very hard problem of valuing a home sight unseen. One way we use multiple “models” is through our hybrid pricing approach, where we have both automated and human-led valuations on a significant fraction of offers. This allows us to scale rapidly while maintaining the accuracy required to deliver a great experience to our customers.
We have also built infrastructure to allow data scientists to prototype, backtest and efficiently implement new valuation models. Among all the models we currently use in production, some of them even have sub-components that are ensemble models themselves!
Interested in working for Opendoor?
If you’re interested in building new models and helping people move rapidly and freely, you should consider joining our team.
Looking to sell a home in South Carolina? Opendoor makes selling simple in Columbia, Western, and Greenville — request a free, no-obligation cash offer.









